近年来,语音深度伪造技术的滥用日益严重,亟需具备强泛化能力的检测方法。然而,现有模型往往依赖特定声码器或与伪造无关的信息(如语义内容、说话人特征),导致在未知声码器和真实场景下性能显著下降。为应对这一问题,研究者提出了解耦表示学习(DRL)与元学习(Meta-learning)等策略:前者通过分离无关因素以提取通用伪造特征,后者通过模拟分布变化以提升模型适应性。
基于此,本文提出 ALDEN(Dual-Level Disentanglement with Meta-learning) 框架,融合双层解耦与元学习机制,联合学习声码器无关特征与合成相关线索,从而显著提升检测器在未知声码器及真实场景中的泛化能力(见图1)。

图1. ALDEN 通过双层解耦与元学习协同,聚焦学习声码器无关特征和合成相关特征。
ALDEN框架主要包括三个核心模块:基于对抗训练的解耦学习(ADL)模块、基于重构的解耦学习(RDL)模块、声码器无关的元学习(VAML)模块。整体框架流程如图2所示。
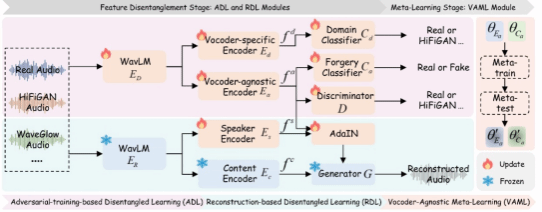
图2. ALDEN框架的Pipeline示意图
为了在低层语音信号中解耦出良好泛化性的伪造痕迹,ADL模块采用多任务学习策略,包含声码器无关编码器和声码器相关编码器。前者学习通用伪造特征,后者识别具体声码器类别。通过对抗训练,声码器无关编码器被迫生成域判别器无法区分的特征,从而有效剥离声码器信息。
在语音伪造检测中,语义内容和说话人身份往往削弱泛化性。为抑制这些无关因素,RDL模块通过内容编码器、说话人编码器与语音生成器的重构任务,将语义信息从声码器无关特征中分离,保留关键的合成痕迹。
最后,VAML模块采用元学习框架,将训练数据划分为元训练集与元测试集,以模拟声码器分布变化。该策略促使模型在不同声码器域间快速适应,进一步提升对未知声码器的泛化能力。
表1 跨声码器场景下ADD模型的EER (%)性能对比

从表1可以看出,ALDEN在五个跨声码器数据集上均取得优异表现,平均EER仅为6.22%,显著优于其他ADD模型,充分验证了其在跨声码器检测任务中的卓越泛化能力。
表2. ALDEN 框架各组件的EER(%)消融结果
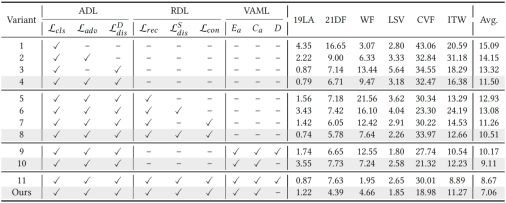
为验证 ALDEN 框架中各模块的作用,我们进行了系列消融实验(见表2)。结果显示:单独使用 ADL(变体4)虽能带来一定改进,但整体性能仍有限;在 ADL 的基础上分别加入 RDL(变体8)或 VAML(变体10)均能进一步提升性能,证明高层语义解耦与元学习策略的有效性;当三者联合(ALDEN框架)时,平均EER降至7.06%,表明三个模块相互补充,协同提升了模型的泛化检测能力。
论文信息
该研究工作已被ACMMM 2025接收,作者为深圳大学的许裕雄、李斌(通讯作者)、李伟祥,米兰理工大学的Sara Mandelli、Viola Negroni,以及软牛科技的李盛。
Yuxiong Xu, Bin Li, Weixiang Li, Sara Mandelli, Viola Negroni, Sheng Li. ALDEN: Dual-Level Disentanglement with Meta-learning for Generalizable Audio Deepfake Detection. ACM MM 2025.


